





I wanted to understand what separates working code from good code. So I used VibeCodeArena.ai to pick a problem statement where different LLMs produce code for the same prompt. Upon landing on the main page of VibeCodeArena, I could see different challenges. Since I was interested in an Image carousal application, I picked the challenge with the prompt "Make a simple image carousel that lets users click 'next' and 'previous' buttons to cycle through images."
Within seconds, I had code from multiple LLMs, including DeepSeek, Mistral, GPT, and Llama. Each code sample also had an objective evaluation score. I was pleasantly surprised to see so many solutions for the same problem. I picked gpt-oss-20b model from OpenAI. For this experiment, I wanted to focus on learning how to code better so either one of the LLMs could have worked. But VibeCodeArena can also be used to evaluate different LLMs to help make a decision about which model to use for what problem statement.
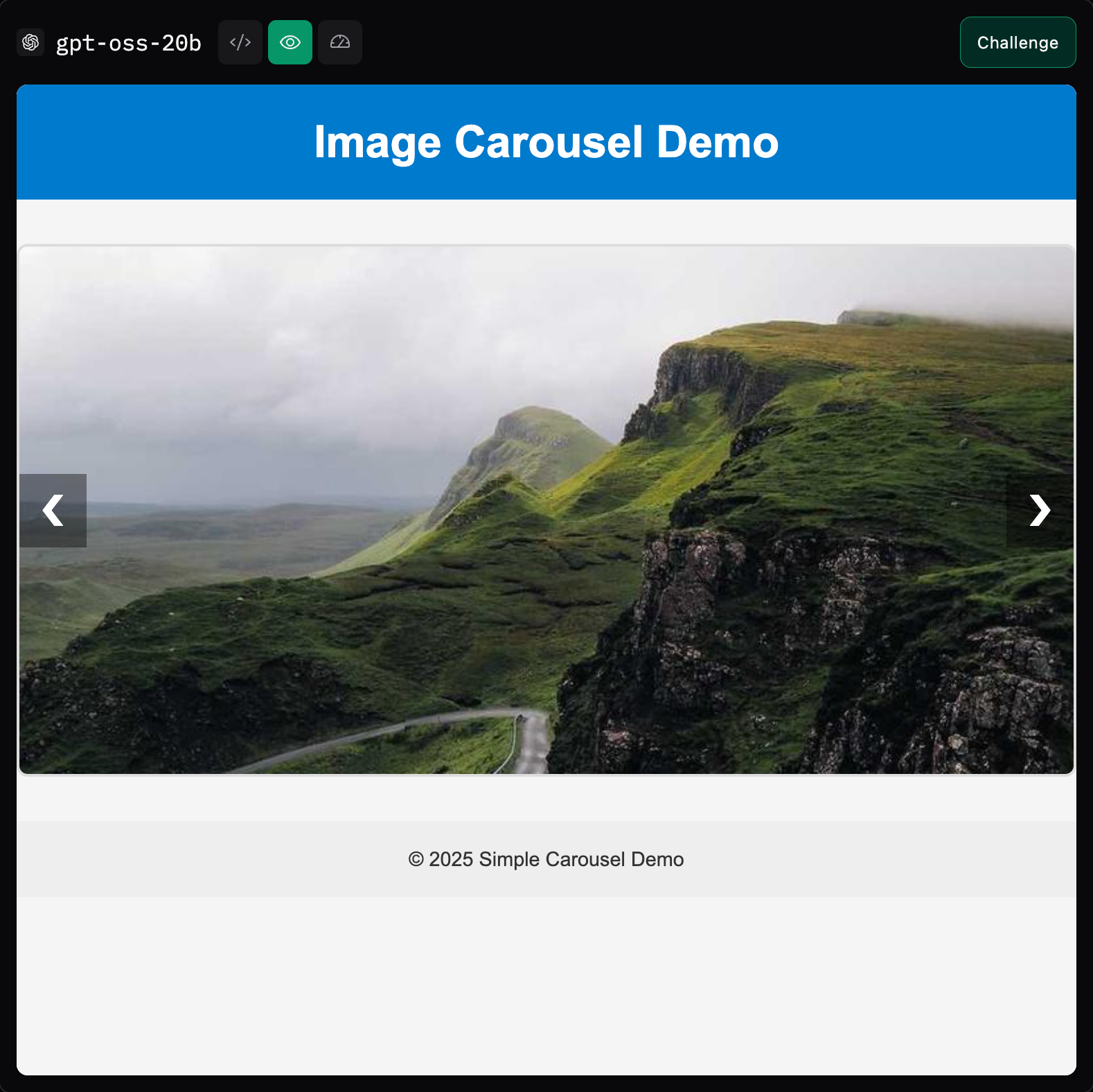
The model had produced a clean HTML, CSS, and JavaScript. The code looked professional. I could see the preview of the code by clicking on the render icon. It worked perfectly in my browser. The carousel was smooth, and the images loaded beautifully.
But was it actually good code?
I had no idea. That's when I decided to look at the evaluation metrics
A working image carousel with:
It looked like something a senior developer would write. But I had questions:
Was it secure? Was it optimized? Would it scale? Were there better ways to structure it?
Without objective evaluation, I had no answers. So, I proceeded to look at the detailed evaluation metrics for this code
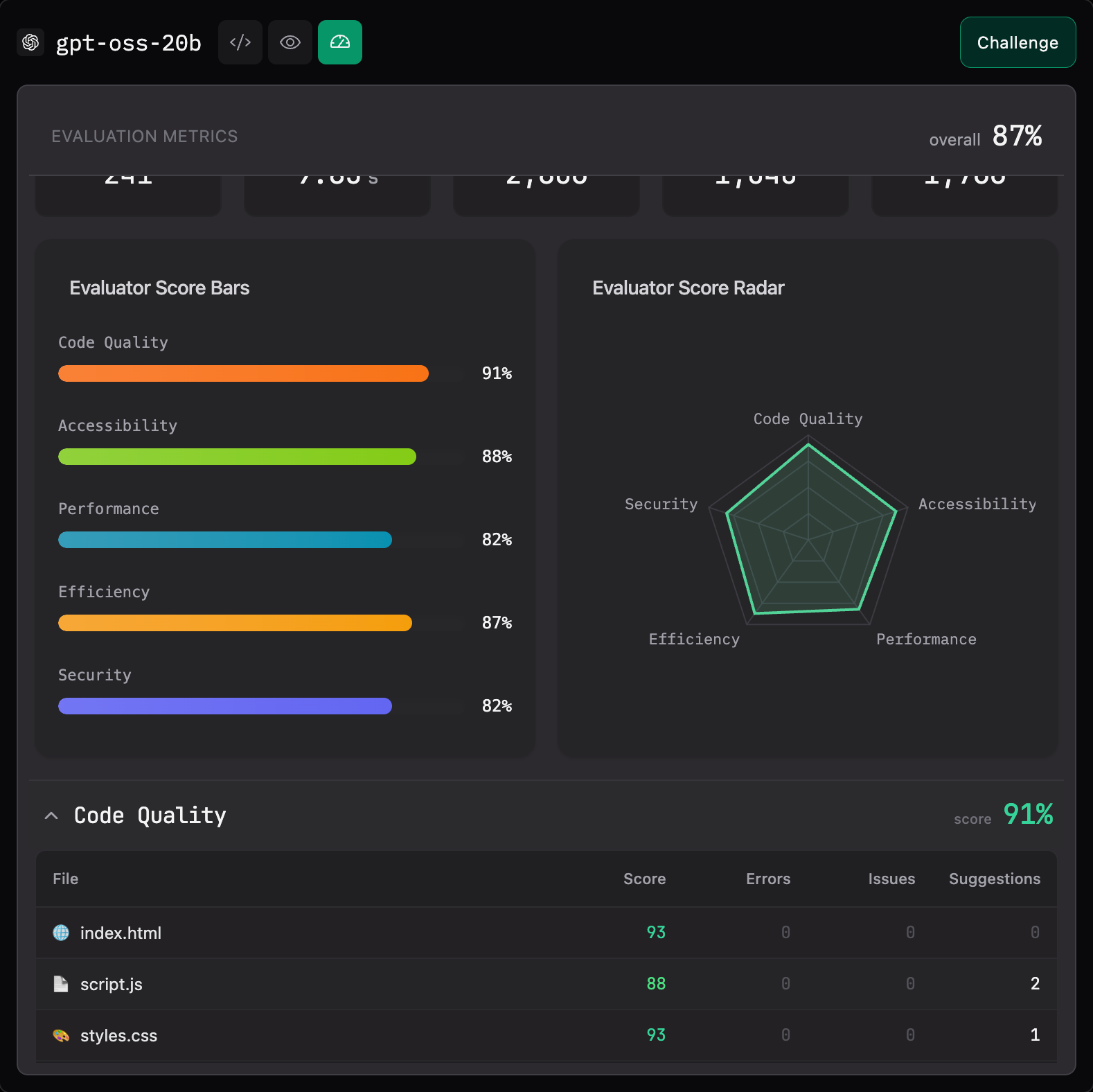
The platform's objective evaluation revealed issues I never would have spotted:
No Content Security Policy (CSP): My carousel was wide open to XSS attacks. Anyone could inject malicious scripts through the image URLs or manipulate the DOM. VibeCodeArena flagged this immediately and recommended implementing CSP headers.
Missing Input Validation: The platform pointed out that while the code handles image errors, it doesn't validate or sanitize the image sources. A malicious actor could potentially exploit this.
Hardcoded Configuration: Image URLs and settings were hardcoded directly in the code. The platform recommended using environment variables instead - a best practice I completely overlooked.
SQL Injection Vulnerability Patterns: Even though this carousel doesn't use a database, the platform flagged coding patterns that could lead to SQL injection in similar contexts. This kind of forward-thinking analysis helps prevent copy-paste security disasters.
DOM Structure Depth (15 levels): VibeCodeArena measured my DOM at 15 levels deep. I had no idea. This creates unnecessary rendering overhead that would get worse as the carousel scales.
Expensive DOM Queries: The JavaScript was repeatedly querying the DOM without caching results. Under load, this would create performance bottlenecks I'd never notice in local testing.
Missing Performance Optimizations: The platform provided a checklist of optimizations I didn't even know existed:
Each of these seems minor, but together they compound into a poor user experience.
High Nesting Depth (4 levels): My JavaScript had logic nested 4 levels deep. VibeCodeArena flagged this as a maintainability concern and suggested flattening the logic.
Overly Specific CSS Selectors (depth: 9): My CSS had selectors 9 levels deep, making it brittle and hard to refactor. I thought I was being thorough; I was actually creating maintenance nightmares.
Code Duplication (7.9%): The platform detected nearly 8% code duplication across files. That's technical debt accumulating from day one.
Moderate Maintainability Index (67.5): While not terrible, the platform showed there's significant room for improvement in code maintainability.
The platform also flagged missing elements that separate hobby projects from professional code:
Here's what hit me: I had no framework for evaluating code quality beyond "does it work?"
The carousel functioned. It was accessible. It had error handling. But I couldn't tell you if it was secure, optimized, or maintainable.
VibeCodeArena gave me that framework. It didn't just point out problems, it taught me what production-ready code looks like.
This is when I discovered the real power of the platform. Here's my process now:
I start with a prompt and let the AI generate the initial solution. This gives me a working baseline.
I can get comprehensive analysis across:
This is where I learn. Each issue includes explanation of why it matters and how to fix it.
Here's the game-changer: I click the "Challenge" button and start fixing the issues based on the suggestions. This turns passive reading into active learning.
Do I implement CSP headers correctly? Does flattening the nested logic actually improve readability? What happens when I add dns-prefetch hints?
I can even use AI to help improve my code. For this action, I can use from a list of several available models that don't need to be the same one that generated the code. This helps me to explore which models are good at what kind of tasks.
For my experiment, I decided to work on two suggestions provided by VibeCodeArena by preloading critical CSS/JS resources with <link rel="preload"> for faster rendering in index.html and by adding explicit width and height attributes to images to prevent layout shift in index.html. The code editor gave me change summary before I submitted by code for evaluation.
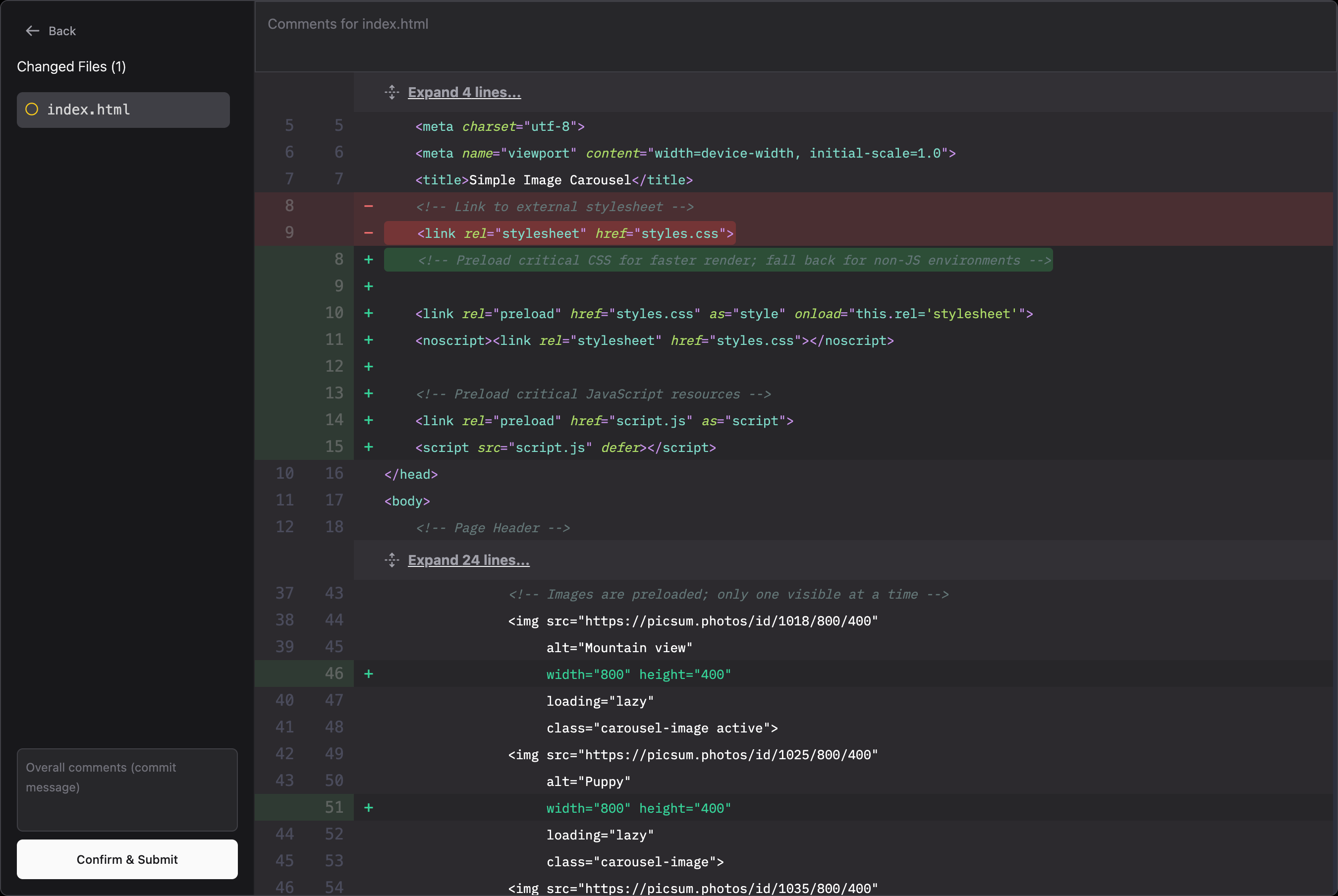
After making improvements, I submit my code for evaluation. Now I see:
My changes helped improve the performance metric of this simple code from 82% to 83% - Yay! But this was just one small change. I now believe that by acting upon multiple suggestions, I can easily improve the quality of the code that I write versus just relying on prompts.
Each improvement can move me up the leaderboard. I'm not just learning in isolation—I'm seeing how my solutions compare to other developers and AI models.
So, this is the loop: Generate → Analyze → Challenge → Improve → Measure → Repeat.
Every iteration makes me better at both evaluating AI code and writing better prompts.
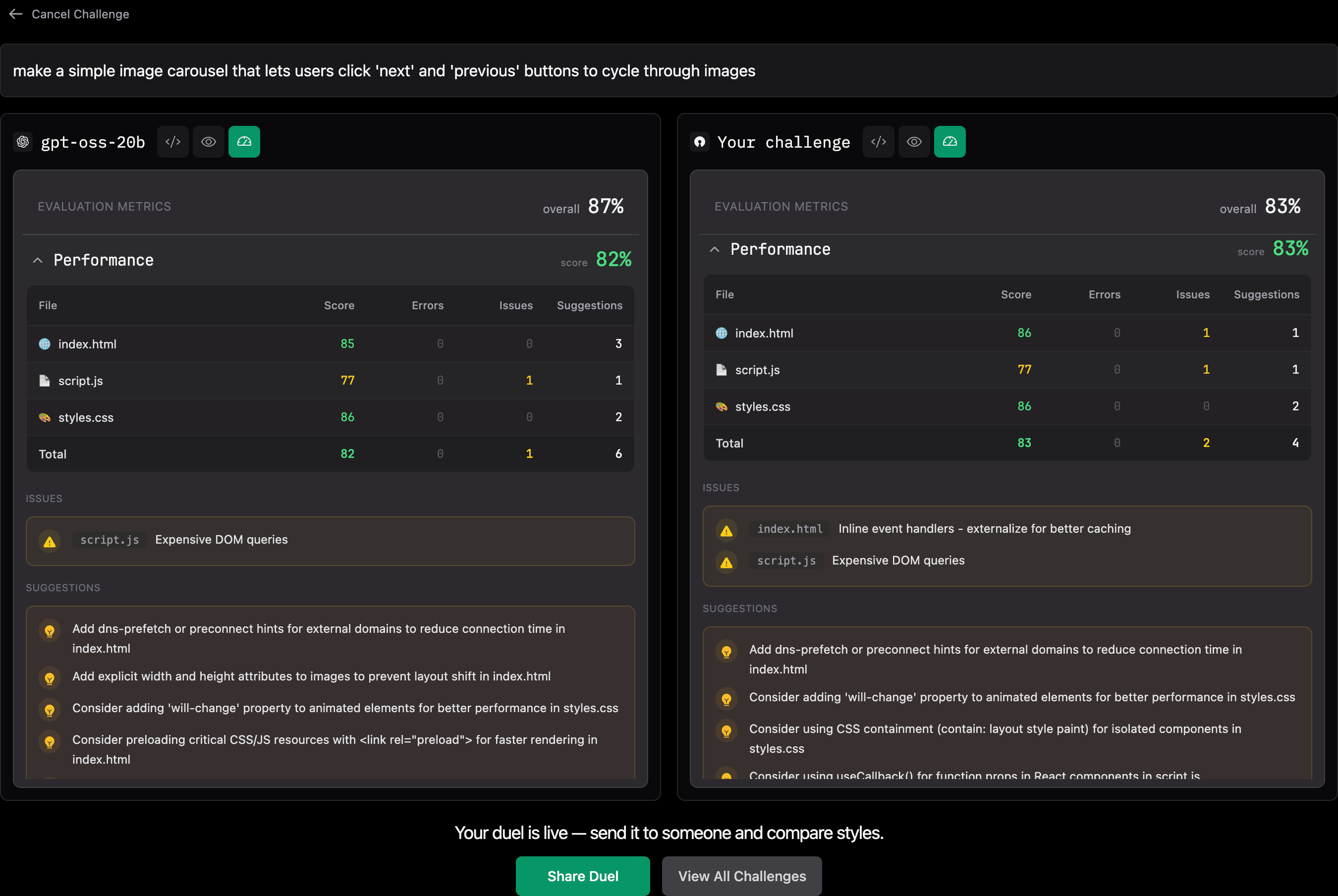
This experience taught me three critical lessons:
AI models are incredible at generating code that functions. But "it works" tells you nothing about security, performance, or maintainability.
The gap between "functional" and "production-ready" is where real learning happens. VibeCodeArena makes that gap visible and teachable.
I used to iterate on code blindly: "This seems better... I think?"
Now I know exactly what improved. When I flatten nested logic, I see the maintainability index go up. When I add CSP headers, I see security scores improve. When I optimize selectors, I see performance gains.
Measurement transforms vague improvement into concrete progress.
The leaderboard changed everything for me. I'm not just trying to write "good enough" code—I'm trying to climb past other developers and even beat the AI models.
This competitive element keeps me pushing to learn one more optimization, fix one more issue, implement one more best practice.
VibeCodeArena isn't just an evaluation tool—it's a structured learning environment. Here's what makes it effective:
Immediate Feedback: I see issues the moment I submit code, not weeks later in code review.
Contextual Education: Each issue comes with explanation and guidance. I learn why something matters, not just that it's wrong.
Iterative Improvement: The "Challenge" button transforms evaluation into action. I learn by doing, not just reading.
Measurable Progress: I can track my improvement over time—both in code quality scores and leaderboard position.
Comparative Learning: Seeing how my solutions stack up against others shows me what's possible and motivates me to reach higher.
Through this iterative process, I've gained practical knowledge I never would have developed just reading documentation:
Each "Challenge" cycle teaches me something new. And because I'm measuring the impact, I know what actually works.
AI coding tools are incredible for generating starting points. But they don't produce high quality code and can't teach you what good code looks like or how to improve it.
VibeCodeArena bridges that gap by providing:
✓ Objective analysis that shows you what's actually wrong
✓ Educational feedback that explains why it matters
✓ A "Challenge" system that turns learning into action
✓ Measurable improvement tracking so you know what works
✓ Competitive motivation through leaderboards
My "simple image carousel" taught me an important lesson: The real skill isn't generating code with AI. It's knowing how to evaluate it, improve it, and learn from the process.
The future of AI-assisted development isn't just about prompting better. It's about developing the judgment to make AI-generated code production-ready. That requires structured learning, objective feedback, and iterative improvement. And that's exactly what VibeCodeArena delivers.
Here is a link to the code for the image carousal I used for my learning journey
#AIcoding #WebDevelopment #CodeQuality #VibeCoding #SoftwareEngineering #LearningToCode

Vibe coding is a new method of using natural language prompts and AI tools to generate code. I have seen firsthand that this change makes software more accessible to everyone. In the past, being able to produce functional code was a strong advantage for developers. Today, when code is produced quickly through AI, the true value lies in designing, refining, and optimizing systems. Our role now goes beyond writing code; we must also ensure that our systems remain efficient and reliable.
I recall the early days when every line of code was written manually. We progressed from machine language to high-level programming, and now we are beginning to interact with our tools using natural language. This development does not only increase speed but also changes how we approach problem solving. Product managers can now create working demos in hours instead of weeks, and founders have a clearer way of pitching their ideas with functional prototypes. It is important for us to rethink our role as developers and focus on architecture and system design rather than simply on typing c

I have experienced both sides of vibe coding. In cases where the goal was to build a quick prototype or a simple internal tool, AI-generated code provided impressive results. Teams have been able to test new ideas and validate concepts much faster. However, when it comes to more complex systems that require careful planning and attention to detail, the output from AI can be problematic. I have seen situations where AI produces large volumes of code that become difficult to manage without significant human intervention.
AI-powered coding tools like GitHub Copilot and AWS’s Q Developer have demonstrated significant productivity gains. For instance, at the National Australia Bank, it’s reported that half of the production code is generated by Q Developer, allowing developers to focus on higher-level problem-solving . Similarly, platforms like Lovable or Hostinger Horizons enable non-coders to build viable tech businesses using natural language prompts, contributing to a shift where AI-generated code reduces the need for large engineering teams. However, there are challenges. AI-generated code can sometimes be verbose or lack the architectural discipline required for complex systems. While AI can rapidly produce prototypes or simple utilities, building large-scale systems still necessitates experienced engineers to refine and optimize the code.
The democratization of code generation is altering the economic landscape of software development. As AI tools become more prevalent, the value of average coding skills may diminish, potentially affecting salaries for entry-level positions. Conversely, developers who excel in system design, architecture, and optimization are likely to see increased demand and compensation.
Seizing the Opportunity
Vibe coding is most beneficial in areas such as rapid prototyping and building simple applications or internal tools. It frees up valuable time that we can then invest in higher-level tasks such as system architecture, security, and user experience. When used in the right context, AI becomes a helpful partner that accelerates the development process without replacing the need for skilled engineers.
This is revolutionizing our craft, much like the shift from machine language to assembly to high-level languages did in the past. AI can churn out code at lightning speed, but remember, “Any fool can write code that a computer can understand. Good programmers write code that humans can understand.” Use AI for rapid prototyping, but it’s your expertise that transforms raw output into robust, scalable software. By honing our skills in design and architecture, we ensure our work remains impactful and enduring. Let’s continue to learn, adapt, and build software that stands the test of time.
Ready to streamline your recruitment process? Get a free demo to explore cutting-edge solutions and resources for your hiring needs.


The question that arises is - "Can organizations continue to leverage AI-driven tools for online assessments without compromising on the integrity of their hiring process? "
This article will discuss the common methods candidates use to outsmart online assessments. We will also dive deep into actionable steps that you can take to prevent cheating while delivering a positive candidate experience.


Last week when I sharedThe top programming languages that will be mostpopular in 2017, the frequent comment was, what does it take to be a better developer?
I’ve met some amazing developers in real life and through React Native Community, and I decided to ask them, “How do I become a better developer?” Thank you to everyone who took the time to answer these questions with passion!
This is a compilation of answers I received from them. Some of these quotes are not limited to answers from that specific question.


Aravind is an undergrad at UC Berkeley pursuing a degree in Electrical Engineering and Computer Science and is Engineering Director for the nonprofit organization Pioneers in Engineering.
Q: How do you think I can become a better developer?
A: Obviously, never stay complacent with what you know – this field changes ridiculously fast, and you need to keep up with it. Follow along with the news in the tech industry, perhaps read up on some source code for a Python module that you recently used.
A friend of mine had some free time over winter break, so he decided to teach himself Django and build a webapp that he could interact with over SMS. It’s sort of a toy project, but he really enjoyed learning the different development paradigms. For context, he specializes in embedded systems and robotics, so this is nowhere near his comfort zone.
But pushing yourself to try different things will make you much stronger as an engineer. I personally wish I had done more web stuff before this year – in my organization (PiE), we’re developing a new iteration of a robotics kit to be used by high school students. While I have a good grasp of the low-level and systems stuff, I’m at a loss when it comes managing our UI design. Never had an interest in doing that type of stuff full-time, but having even a surface-level knowledge can be immensely helpful
Q: Do you have any projects you did to push yourself out of your comfort zone?
A: I built an automated door opener last summer, which operated a mechanical lever to open a door when an RFID card was scanned. The project used a really powerful motor and a mess of sensors to track the state of the arm, which proved to be quite difficult to coordinate. I learned real quick that I would need to do a bunch of offline testing before running my code on the device, which was very different from what I was used to up till then.
In terms of academics, I just finished CS 189, which was a massive crash course in data science, optimization, and probability theory. The programming I did in that class was also very different from what I’m used to, even though it was all in Python.

Brent is Front-end web/mobile developer working on Exponent and React Native. He contributes to tons of open-source projects.
Q: I really want to become a better developer; what would you say the first step is?
A: Do stuff you’re excited about and contribute to open source projects:-D
Q: How old are you and how much experience do you have as a programmer?
A: I am 30 years old, and very much 😮
Q: How did you join Exponent? What was the cause?
A: James (ide) and I were the most active contributors to a react-native outside of facebook and so we spoke a lot. He created exponent with Charlie. I ended up doing some consulting work with them and Charlie asked if I’d be interested in working with them full time and year, it was lots of fun so I joined.
Q: I should know objective C and Java thoroughly before I jump into React Native, right?
A: You can learn it as you go if you need to. there’s also tons of pure javascript stuff that need to be done. and documentation. lots of things 🙂

Charlie Cheever is the co-founder of Quora, an online knowledge market. He was formerly an engineer and manager at Facebook, where he oversaw the creation of Facebook Connect and the Facebook Platform. Prior to Facebook, Cheever was employed by Amazon.com in Seattle. He left Facebook to start Quora in June 2009 to work on Exponent.
Q: What’s the motivation of Exponent being free and Open Source?
A: I really want to make something that like a 12-year-old version of me would use. So, someone who doesn’t know tons about programming but can learn new things and doesn’t have a credit card or lots of money, but has time and creativity and a phone and friends. I learned to program making calculator games on TI-85, it’s sad to me that kids can’t make stuff on their phones today.
Q: Why did you leave Quora?
A: I managed the mobile teams there and it was so slow to work on those apps even tho we had good people, I found it so frustrating And after I left I tried to build some mobile stuff and it was so annoying that I decided there needed to be a different way to make stuff. So James and I made something like react Native called Ion. It was strikingly similar actually. But React Native already had android support and 20 people working on it, and we had 2 people. So we decided to make everything else around it that we wanted to make!
Q: What did you do on Facebook?
A: I made the developer platform that all those games like FarmVille were on. Well, not all of it obviously but was one of two main developers. And I worked on the first version of facebook video, then did a lot of random other things. Then was a manager and did log in with Facebook on other sites, and then left to do Quora.


Christopher has been working at Facebook as a Front-end Engineer for about 5 years. Previously, he worked at Curse Network.
Q: What do you do on Facebook?
A: I was on the photos team when I started, then I discovered React and started adopting and promoting it both internally and externally. I was there at the beginning of reacting native and pushed it through until 3 months ago. I just recently switched to the Nuclide team. I’m still #3 contributor on React Native.😛
Q: Do you have any prior work experience?
A: I was working for Curse (doing website for blizzard games) during my college to pay for it. It was fun to see the company go from 5 people in a guild to a 100 people company.
Q: What’s your day to day like on Facebook? The current project you’re working on?
A: I’m currently working on the Nuclide team, Facebook’s IDE built on top of Atom. I would say my time is spent half coding, half cheerleading all the cool stuff people are doing inside of FB.
Q: How do you think one can become a better developer?
A: I think that there are multiple levels.
The first level is mastering all the concepts. For example yesterday I had to write a function that removes certain keys from a big nested object. Because I’ve done this task so many times in the past, I was able to implement it in one go without even thinking and it worked the first time. For this one, exercises are really good. You want to code the same kind of things many many times to train your muscle memory.
The second level is how do you build things in a way that are not going to break in the future. Ideally, once you build something, you can move to the next thing and it’ll keep working without you there. This is challenging when there’s a ton of developers touching the codebase and product directions changing often.
Finally, the third level is how do you prevent a whole class of problems from even existing in the first place. A good example is with manual dom mutations, it’s very easy to trigger some code that interacts with a dom node that has been removed from the dom. React came in and made this problem go away. You have to go out of your way to do so, and even if you want to do those things, you have the tools to make it work: lifecycle events.
Q: Is there something you wish you’d known or learned earlier as a programmer?
A: Probably the most important thing is: tradeoffs, tradeoffs, tradeoffs. They are everywhere.
If you are working on some random throwaway feature that no one is going to use, who cares if the code is maintainable, you need it to work and now one mistake I see a lot is that people over-engineer the easy things but are not willing to make their architecture less clean from a CS perspective even though it actually provides the user experience you need.
At the end of the day, we write all this code for the users, we should first understand what the user experience should be and then do whatever it takes to get it. If the user just needs to display some content and needs to be able to edit it easily, just install WordPress, pick a good looking theme and call it a day
– Btw, pro-tip, if you want to be successful, always think about the value you are providing. If you are earning $100k a year, this means that the company should be making $200k because you’re here

Dan is a Senior Back-end developer @Futuri Media. He has 20 years of programming experience in many different languages. He’s been contributing to React Native early/mid-2015.
Q: What’s your background as a programmer?
A: I started learning to program (with QBasic) when I was 11 and was hooked. I learned everything I could, as fast as I could. I learned a few languages like Visual Basic and started to dabble with C and C++. Then I found web development and dove in head first. First, learning HTML and CSS, then adding simple CGI scripts written in Perl, and eventually Classic ASP.
My first paying project was when I was 14: A website for the company my dad worked for, with a customer portal to let them see their job progress. This was all in ASP. After that, I started learning PHP, and have been using that as my language of choice ever since. However, I picked up a lot of experience with other languages along the way: JS, Python, Ruby (on Rails), Java, C#, Go, Objective-C.
Q: What are some projects you’re currently working on?
A: I work for Future Media (http://futurimedia.com). We provide SaaS solutions for Broadcast Radio and TV companies. We provide white label mobile applications, social engagement and discovery, audio streaming and podcast solutions, etc. I haven’t had much free time lately to contribute to many OSS projects, but hope to change that soon!
Currently, I am a Senior Back-End Web Developer, but I am transitioning into being the Director of Technical Operations.
Q: Is there something you wish you’d learned or knew earlier as a developer?
A: I wished I would have realized earlier in my career that it is OK to be wrong, and that failure is just a chance to learn.
Q: What’s the first step to becoming a good developer?
A: Come up with a small-ish project that you think would be cool, or would make your life easier, and just jump right in. Too many people try to learn without a goal other than “I want to learn to code.” Without a goal, you are just reading docs or copy/pasting from tutorials…you can’t learn that way.
To become a better developer, you need to do one simple thing: Never. Stop. Learning. Read other people’s code, figure out how that one app does that really cool thing you saw, read blogs, etc. No matter how good you are, or think you are, there is always someone better, and always more to learn.
Q: Is there a certain project you’re currently interested in? Next on your learning list?
A: I have been using, and occasionally contributing to, React Native since early/mid-2015, and continue to be interested in it.
Next, on my learning list is learning Erlang/Elixir. We build heavily distributed systems where I work and think we would really benefit from a language like that.
Frank is a lead architect for BNY Mellon by day and the author of eight books on various programming topics for Apress by night
Q: How do I become a better developer?
A: I get asked this question quite a bit both at work from junior developers and from readers of my books. I always give the same answer: make games!
It sounds like a joke answer, but it most definitely is not! Games have a unique ability to touch on so many software engineering topics that you can’t help but learn things from the experience. Whether it’s choosing proper data structures and algorithms, or writing optimized code (without getting lost in micro-optimizations – at least too soon), or various forms of AI, it’s all stuff that is more broadly applicable outside of games. You frequently deal with network coding, obviously audio and visual coding (which tends to open your mind to mathematical concepts you otherwise might not be), efficient I/O and of course overall architecture, which has to be clean and efficient in games (and for many games, extensible). All those topics and more are things that come into play (hehe) when making games.
It also teaches you debugging and defensive programming techniques extremely well because one thing people don’t accept in games is errors. It’s kind of ironic actually: people will deal with some degree of imperfection in their banking website but show a single glitch in a game and they hate it! You have no choice but to write solid code in a game and you figure out what works and what doesn’t, how to recover from unexpected conditions, how to spot edge cases, all of that. It all comes into play and those are skills that developers need generally and which I find are most frequently lacking in many developers.
It doesn’t matter one bit if the game you produce is any good, or whether anyone else ever even plays it. It doesn’t matter if it’s web-based (even if your day job is), or mobile, doesn’t matter what technologies you use. The type of insight and problem-solving skills you build and tune when creating games will serve you well no matter what your day job is, even in ways that are far from obvious.
I’ve been programming games for the better part of 35 years now. No, none of them have been best-sellers or won awards or anything like that. In fact, it’s a safe bet that most people wouldn’t have even heard of my games, even the one’s still available today. None of that matters because the experience of building them is far and away the most rewarding part of it. Perhaps the best thing about programming games is that they are, by their nature, fun! You’re creating something that’s intended to be enjoyable so the process of creating it should absolutely be just as enjoyable. How many things can you do that are really fun while still being challenging and simultaneously help build the skills needed for a long career?
So yeah, make games, that’s my simple two-word answer!
Q: Is there something you wish you’d known or learned earlier as a programmer?
A: Hmm, tough question actually. I guess if there was one thing (and I’ll cheat and combine two things here because they’re related) I would say that early on I didn’t understand two very important phrases: “As simple as possible, but no simpler” and “Don’t let the perfect be the enemy of the good”.
I have a natural perfectionist mentality, so I spend a lot of time pondering architecture, API design, etc. I once spent 33 hours straight working on a Commodore 64 demo because ONE lousy pixel was out of place and my perfectionist brain just couldn’t live with it! Sometimes, I have to force myself to say “okay, it’s good enough, you’ve planned enough, now get to work and actually BUILD stuff and refactor it later if needed”, or I have to force myself to say “okay, it basically does what it’s supposed to, it doesn’t need to be absolutely flawless because nobody but me is even going to notice”. Especially when you’ve got deadlines and people relying on you, you have to make sure you’re working towards concrete goals and not constantly getting stuck trying to achieve perfection because you rarely are going to, at least initially anyway, no matter how hard you plan or try – and the dirty little secret in IT is that perfection rarely matters anyway! Good enough is frequently, err, good enough 🙂
And, your design/development approach should always strive to be as absolutely simple as possible. Of course, what constitutes “simple” is debatable and doesn’t necessarily even always have the same meaning from project to project, but for me some key metrics are how many dependencies I have (web development today is a NIGHTMARE in this regard – less is GENERALLY better) and how many layers of abstraction there are. Developers, especially in the Java world, like to abstract everything and they do so under the assumption that it’s more flexible. But if there’s one thing I’ve learned over the years it’s that the way to write flexible code is to write simple code. It’s better than abstractions and extension points and that sort of stuff because it’s just far easier to understand the consequences of your changes.
As a corollary, a terse code is NOT simpler code! Simple code is code that anyone can quickly understand, even less capable developers, and even yourself years after. Terse and “clever” code tends to be the exact opposite. Often times, the more verbose code is actually simpler because there are fewer assumptions and often less knowledge needed to understand it, less “code hoping” you have to do to follow things. Related to this is that writing less code isn’t AUTOMATICALLY better. No, you shouldn’t re-invent the wheel, but you also shouldn’t be AFRAID to invent a marginally better the wheel when it makes sense. Knowing the difference is hard of course and comes from experience, but if you think it’s ALWAYS better to write less code then you’re going to make your life harder in the long run.
Of course, don’t over-simplify code either. Too simple and suddenly extending it almost MUST mean a refactor. You never want to completely refactor because you HAVE to in order to build an app over time. There’s a balance that’s difficult to strike but it should always be the goal.
Oh yeah, and I wish I knew how to express myself in fewer words… but actually, I’m still obviously working on that one 🙂

Janic is the co-founder of App & Flow, a react-native contributor, and open-source contributor.
Q: Any tips to becoming a better developer?
A: Don’t think there’s anything in particular, you just have keep learning and getting out of your comfort zone. Like trying a new language or framework from time to time. At least that’s what I do but I’m pretty sure there are some other good ways haha 🙂
Q: How can I start contributing to React Native?
A: The best is to start with something small like a bug fix or adding a small feature like an extra prop on a component. Most contributors know either iOS or Android and a bit of JS. There are also some JS devs that work on things like the package and clip. We keep some issues with a Good First Task label that should be a good place to start

Jake is an Open-source Archaeologist. He writes buzzword compliant code. Co-founder at @commitocracy.
Q: Hey Jake, any tips to becoming a better programmer? 🙂
A: Number one thing you should do is to learn your tools before you learn the language you work in because it will lead to faster feedback loops and you will get to experience more in less time. So install a linter and it will catch most of your errors as you type. It statically analyzes your code and recommends best practices to follow. You should always follow best practices until you gain enough experience to start questioning them.

Jun is a software engineer at Coupang, which is the $5 Billion Startup Filling Amazon’s Void In South Korea. He is a very friendly developer who loves to connect.
Q: How do you become a better developer?
A: The word ‘better’ can be described in various ways–especially in the field of programming. A good developer could be someone who is exceptionally talented in development, someone who is amazing at communicating, or someone who understands Business very well. I personally think a “good” developer is someone who is in the middle–a person who can solve his or her business problem with their development skills, and communicate with others about the issue. Ultimately, to achieve this, it requires a lot of practice, and I recommend you to create your own service. Looking and thinking from the perspective of the user and improving the service to fulfill their needs really helps you grow as a better developer.
Q: Is there something you wish you’d known or learned earlier as a developer?
A: I really wish I started my own service earlier on. The hardest thing to grasp before developing is realizing how you can apply what you learned. Many developers are afraid to start a “service” because it sounds difficult; however, pondering about what to make and where to start, and then connecting those points of thought help you grow as a better developer.
Q: What do you do at Coupang? What are you currently working on?
A: Coupling provides a rocket-delivery-service, and I am working on developing a system called “Coupling Car,” which is related to insurance and monetary management. Furthermore, I’m thinking about adding transportation control system and the ability to analyze data from the log.

Keon is a student at NYU who is really passionate about Machine Learning. He is a very active GitHub member who tries to contribute to open source projects related to machine learning.
Q: What are your interests? What kind of projects have you worked on?
A: I’ve been working on machine learning projects these days. I am one of the project members of DeepCoding Project, a project with a goal of translating written English to the source code. I’ve been contributing to a C++ machine learning framework called my pack(https://github.com/mlpack/mlpack), which is equivalent to skit-learn in Python.
I’ve also done some fun side projects: DeepStock (https://github.com/keonkim/deepstock) project is an attempt to predict the stock market trends by analyzing daily news headlines. CodeGAN (https://github.com/keonkim/CodeGAN) is a source code generator that uses one of the new deep learning methods called SeqGAN.
Q: How do you become a better developer?
A: I think it is really important to understand the basics. By basics, I mean math, data structures, and algorithms. Deep learning is really hot right now, and I see people jumping into learning it without basic knowledge in computer science and mathematics. And of course, most of them give up as soon as mathematical notations appear in the tutorial. I know this because I was one of them and it took me really long time to understand some concepts that students with a strong fundamentals could understand in a fraction of the time I spent. New languages, libraries, and frameworks are introduced literally every day these days, and you need the fundamentals in order to keep up with them.
Munseok is a Full-stack developer and CTO at Sketchware. He previously worked at System Integration for ~7 years.
Q: How do I become a better developer?
A: When I was very young and cocky, I evaluated other developers based on their coding style. There were certain criteria they had to pass in order for me to judge them as a good developer. But now, I really don’t think that way. Now, I believe that every developer is progressive, which means he or she is becoming a better developer every day. It doesn’t really matter if the style is bad or code is good–as long as the program runs, I think it’s great! Whether the program has room for growth or has bugs, I think the motivation to develop is what really matters. Developers usually are never satisfied with their skills. They are always eager to become better–probably why you’re doing this. It’s really hard to justify “good developer”. People like you will become better than me in no time. I still don’t think I am a good developer.
Q: What was the most difficult thing when you were developing Sketchware?
A: Developing Sketchware wasn’t too difficult because we had a good blueprint for the item. The direction was very clear for us to follow, so developing it was a breeze. However, there was a line we had to maintain for Sketchware–this line had two conditions:
Since we wanted Sketchware to be an efficient tool that can help users learn programming concepts, I am very considerate and think a lot when it comes to adding new features in the application.
Q: As a developer, is there something you wish you knew or fixed earlier?
A: I really wish I jumped into the Start-up world earlier. When it comes to developing, you need to be passionate and really enjoy what you do. Even if you pull 3 all-nighters, ponder all day long about a new algorithm, or stress about a new bug, everything will be okay if you’re enjoying it. It really goes back to the question #1–I get my energy from the joy I have when I develop, and that joy eventually makes you a better developer. When life hits you, most developers lose the passion for developing if you think of it as work. I used to be like that. But now, I’m really not worried–since developing brings joy to me now. Even if we run out of funds or our company burns down, it’s really okay since I am making the most out of what I am doing.

Satyajit is the UX Lead at Glucosio, and Front-end Engineer at Callstack.io. He is an amazing open-source contributor; he is one of the top 5 contributors in React Native
Q: What is your background as a programmer?
A: I don’t really come from a programming background. I did my graduation in Forestry. I left post-graduation after getting a job offer and never looked back.
Q: What’s your day like on day to day basis?
A: It’s pretty boring. I wake up, order some breakfast online or go out, then start office work. In evening I go out to a bar or take a long walk if there’s enough time left. At night I mostly watch TV series or hack on side-projects.
Q: Motivation behind contributing to open source projects?
A: I’ve been involved in Open Source for a long time. When I was doing my graduation I got into Linux and got introduced to the world of Open Source. I loved it how we could learn so much from other projects. It fascinated me that developers were selfless to let us see and use the there code for free (mostly). I did a lot of Open Source projects in form of themes and apps during my college days, and it always made me happy when people forked them and changed to meet their needs, and send pull requests to fix things.
As a developer, I contribute to Open Source projects most of the time because I need a feature, or it improves something on a project I love. I think it’s better if we work together to fix stuff that is important to us rather than just filing issues.
Q: How do I become a better developer?
A: I think it’s important that we are open to new things. There’s a lot to learn, and we cannot learn if we stay in our bubble. Try new things, even if you think you can’t do it, even it looks complex on the surface. I have failed to do things so many times, but eventually succeed. In the process, I understand the problem and the solution, and then it becomes really simple.

Sonny is a JavaScript Full Stack Engineer, a React & React Native player, and an Open source enthusiast. He currently works as an Engineer at Sale Stock.
Q: How do you become a better developer?
A: I think always eager to learn is the key. Try everything, make mistakes, and learn from that mistakes. I agree that code review from partners and senior engineers will make our code better. Try publishing your own open source projects, meet other great developers and learn from them.
Q: What’s your motivation behind creating open source projects?
A: I just want the people to know about our idea, and try implementing it so that others can use our project. I’m really inspired by people that work on open source projects that used by many devs such as Dan Abramov that created redux.
Sunggu worked at Daum Communications for 4 years. Then, he left Daum to work at Scatter Lab as the CTO. This is his 5th year at Scatter Lab.
Q: How do you become a better developer?
A: Hmm… Becoming a good developer… Every developer has his or her own personality when it comes to programming. As an analogy, think about blacksmiths! Not all blacksmiths are alike–some enjoy crafting the best sword, while some might enjoy testing out the sword more than crafting it. I am a thinker–who plans and organizes thoughts before I carry out an action. I think a good developer knows how to write concise and clean code; you should practice this habit. Even though the trend for programming is always changing, and many people use different languages, write a piece of code that anyone can understand without comments.
Q: What do you think is the next BIG thing?
A: I’ve observed the evolution of programming languages, and I think it’s becoming more abstract every generation–procedural programming, imperative programming, functional programming… I think in the future, maybe in about 20 to 30 years, we will live in the time where the computer writes the code for us, and we just put them together like legos.
Q: What should I focus on studying?
A: I think deep learning is a must. Try different tutorials and learn it with passion. Math, algorithms–anything will help you in the long run.

Timothy is a software engineer at Snapchat. He previously worked at many places such as Riot Games, Square, etc.
Q: What do you do at Snapchat?
A: I’m a software engineer on the monetization team, so I work on anything related to making money. Some example projects are Snapchat Discover, a news platform within the iOS and Android apps; Ad Manager, a control panel used by sales and ad operations to flight ads; Ads API, which allows third-party partners to integrate their own ad platforms into Snapchat. Also, I was a past intern at Snapchat so I occasionally give talks and Q&As to upcoming interns. I’m also heavily invested in hiring and conduct a lot of interviews there.
Q: What do you do on a day-to-day basis?
A: What I’ve mentioned previously. Also, even after I pass on the work to other people, sometimes I have to go back and help support it or be part of the technical discussions on future changes. When new people join the team, usually I’m the one to ramp people up on how the code base looks like the kinds of frameworks we use, how a typical engineer workflow looks like, etc.
Q: What languages/framework do you guys mostly use?
A: For server code, it’s usually Java and for UI we use React Redux. Most teams work in google app engine, which is why we use Java, but some teams switch it up a little bit due to some app engine limitations. And of course, the product teams work in objective C for iOS and Java for Android.
Q: How do you think I can become a better developer?
A: I think the best thing to do is to do as many things as possible. I did seven internships while in school so I already had two years of work experience before I graduated. Work experience is super important because coding in a hackathon, doing personal projects, and doing school assignments are totally different than working with enterprise software and apps with real users. But you have to start somewhere, so that’s where going to school, doing personal projects, and competing in hackathons comes in. And while at work, I think the best way to succeed is to ask lots of questions and learn by doing. You can read and study all you want, but you might not understand what’s going on until you actually do it. Another thing is code reviews — you can do so much knowledge transfer by having a more senior engineer tear your code apart and tell you how to make it better. Also, if you ever come up with a proposal on how to solve a problem, getting a tech lead to bombard you with hard questions forces you to make sure you have every little detail covered.
*The article was originally posted by Sung Park on Github*
“There exists a world for Machine Learning beyond R and Python!
Machine Learning is a product of statistics, mathematics, and computer science. As a practice, it has grown phenomenally in the last few years. It has empowered companies to build products like recommendation engines, self driving cars etc. which were beyond imagination until a few years back. In addition, ML algorithms have also given a massive boost to big data analysis.
But, how is ML making all these accomplishments?
After realising the sheer power of machine learning, lots of people and companies have invested their time and resources in creating a supportive ML environment. That's why, we come across several open source projects these days.
You have a great opportunity right now to make most out of machine learning. No longer, you need to write endless codes to implement machine learning algorithms. Some good people have already done the dirty work. Yes, they've made libraries. Your launchpad is set.
In this article, you'll learn about top programming languages which are being used worldwide to create machine learning models/products.
A library is defined as a collection of non-volatile and pre-compiled codes. Libraries are often used by programs to develop software.
Libraries tend to be relatively stable and free of bugs. If we use appropriate libraries, it reduces the amount of code that is to be written. The fewer the lines of code, the better the functionality. Therefore, in most cases, it is better to use a library than to write our own code.
Libraries can be implemented more efficiently than our own codes in algorithms. So people have to rely on libraries in the field of machine learning.
Correctness is also an important feature like efficiency is in machine learning. We can never be sure if an algorithm is implemented perfectly after reading the original research paper twice. An open source library consists of all the minute details that are dropped out of scientific literature.

Python is an old and very popular language designed in 1991 by Guido van Rossum. It is open source and is used for web and Internet development (with frameworks such as Django, Flask, etc.), scientific and numeric computing (with the help of libraries such as NumPy, SciPy, etc.), software development, and much more.
Let us now look at a few libraries in Python for machine learning:
It was started in 2007 by David Cournapeau as a Google Summer of Code project. Later in 2007, Matthieu Brucher started to work on this project as a part of his thesis. In 2010, Fabian Pedregosa, Gael Varoquaux, Alexandre Gramfort, and Vincent Michel of INRIA took the leadership of the project. The first edition was released on February 1, 2010. It is built on libraries such as NumPy, SciPy, and Matplotlib.
Features:
A few companies that use scikit-learn are Spotify, Evernote, Inria, and Betaworks.
Official website: Click here
It was initially released on November 9, 2015, by the Google Brain Team. It is a machine learning library written in Python and C++.
Features:
It is used by companies like Google, DeepMind, Mi, Twitter, Dropbox, eBay, Uber, etc.
Official Website: Click here
It is an open source Python library that was built at the Université de Montréal by a machine learning group. Theano is named after the Greek mathematician, who may have been Pythagoras’ wife. It is in tight integration with NumPy.
Features:
A few companies that use Theano are Facebook, Oracle, Google, and Parallel Dots.
Official Website: Click here
Caffe is a framework for machine learning in vision applications. It was created by Yangqing Jia during his PhD at UC Berkeley and was developed by the Berkeley Vision and Learning Center.
Features:
It is used by companies such as Flicker, Yahoo, and Adobe.
Official Website: Click here
The GraphLab Create is a Python package that was started by Prof. Carlos Guestrin of Carnegie Mellon University in 2009. It is now known as Turi and was known as Dato before this. GraphLab Create is a commercial software that comes with a free one year subscription (for academic use only). It allows to perform end-to-end large scale data analysis and data product development.
Features:
Official Website: Click here
There are numerous other notable Python libraries for machine learning such as Pattern, NuPIC, PythonXY, Nilearn, Statsmodels, Lasagne, etc.
R is a programming language and environment built for statistical computing and graphics. It was designed by Robert Gentleman and Ross Ihaka in August 1993. It provides a wide variety of statistical and graphical techniques such as linear and nonlinear modeling, classical statistical tests, time-series analysis, classification, clustering, etc. It is a free software.
Following are a few packages in R for machine learning:
The caret package (short for Classification And REgression Training), was written by Max Kuhn. Its development started in 2005. It was later made open source and uploaded to CRAN. It is a set of functions that attempt to unify the process for predictive analysis.
Features:
Official Website: Click here
It stands for Machine Learning in R. It was written by Bernd Bischl. It is a common interface for machine learning tasks such as classification, regression, cluster analysis, and survival analysis in R.
Features:
Official Website: Click here
It is the R interface for H2O. It was written by Spencer Aiello, Tom Kraljevic and Petr Maj, with the contributions from the H2O.ai team. H2O makes it easy to apply machine learning and predictive analytics to solve the most challenging business problems. h2o is an R scripting functionality for H2O.
Features:
Official Website: Click here
Other packages in R that are worth considering for machine learning are e1071, rpart, nnet, and randomForest.
Go language is a programming language which was initially developed at Google by Robert Griesemer, Rob Pike, and Ken Thompson in 2007. It was announced in November 2009 and is used in some of Google's production systems.
It is a statically typed language which has a syntax similar to C. It provides a rich standard library. It is easy to use but the code compiles to a binary that runs almost as fast as C. So it can be considered for tasks dealing with large volumes of data.
Below is a list of libraries in Golang which are useful for data science and related fields:
GoLearn is claimed as a batteries included machine learning library for Go. The aim is simplicity paired with customizability.
Features:
Official Website: Click here
Gorgonia is a library in Go that helps facilitate machine learning. Its idea is quite similar to TensorFlow and Theano. It is low-level but has high goals.
Features:
Official website: Click here
goml is a library for machine learning written entirely in Golang. It lets the developer include machine learning into their applications.
Features:
Official Website: Click here
There are other libraries too that can be considered for machine learning such as gobrain, goglaib, gago, etc.
Java is a general-purpose computer programming language. It was initiated by James Gosling, Mike Sheridan, and Patrick Naughton in June 1991. The first implementation as Java 1.0 was released in 1995 by Sun Microsystems.
Some libraries in Java for machine learning are:
It stands for Waikato Environment for Knowledge Analysis. It was created by the machine learning group at the University of Waikato. It is a library with a collection of machine learning algorithms for data mining tasks. These algorithms can either be applied directly to a dataset or we can call it from our own Java code.
Features:
Official Website: Click here
It stands for Java Data Mining Package. It is a Java library for data analysis and machine learning. Its contributors are Holger Arndt, Markus Bundschus, and Andreas Nägele. It treats every type of data as a matrix.
Features:
Official Website: Click here
MLlib is a machine learning library for Apache Spark. It can be used in Java, Python, R, and Scala. It aims at making practical machine learning scalable and easy.
Features:
It is used by Oracle.
Official Website: Click here
Other libraries: Java-ML, JSAT
Bjarne Stroustrup began to work on "C with Classes" which is the predecessor to C++ in 1979. "C with Classes" was renamed to "C++" in 1983. It is a general-purpose programming language. It has imperative, object-oriented, and generic programming features, and it also provides facilities for low-level memory manipulation.
mlpack is a machine learning library in C++ which emphasizes scalability, speed, and ease of use. Initially, it was produced by the FASTLab at Georgia Tech. mlpack was presented at the BigLearning workshop of NIPS 2011 and later published in the Journal of Machine Learning Research.
Features:
Official Website: Click here
Shark is a C++ machine learning library written by Christian Igel, Verena Heidrich-Meisner, and Tobias Glasmachers. It serves as a powerful toolbox for research as well as real-world applications. It depends on Boost and CMake.
Features:
Official Website: Click here
It is a machine learning toolbox developed in 1999 initiated by Soeren Sonnenburg and Gunnar Raetsch.
Features:
Official Website: Click here
Other libraries: Dlib-ml, MLC++
Julia is a high-performance dynamic programming language designed by Jeff Bezanson, Stefan Karpinski, Viral Shah, and Alan Edelman. It first appeared in 2012. The Julia developer community is contributing a number of external packages through Julia's built-in package manager at a rapid pace.
The scikit-learn Python library is a very popular library among machine learning researchers and data scientists. ScikitLearn.jl brings the capabilities of scikit-learn to Julia. The primary goal of it is to integrate Julia and Python-defined models together into the scikit-learn framework.
Features:
Official Website: Click here
It is a library that aims to be a general-purpose machine learning library for Julia with a number of support tools and algorithms.
Features:
Official Website: Click here
It is said to be "a swiss knife for machine learning". It is a Julia package which provides useful tools for machine learning applications.
Features:
Official Website: Click here
Scala is another general-purpose programming language. It was designed by Martin Odersky and first appeared on January 20, 2004. The word Scala is a portmanteau of scalable and language which signifies that it is designed to grow with the demands of its users. It runs on JVM, hence Java and Scala stacks can be mixed. Scala is used in data science.
Here's a list of a few libraries in Scala that can be used for machine learning.
ScalaNLP is a suite of machine learning, numerical computing libraries, and natural language processing. It includes libraries like Breeze and Epic.
Official Website: Click here
This is not an exhaustive list. There are various other languages such as SAS and MATLAB where one can perform machine learning.
In 1995, JavaScript emerged as programming language to create web pages. Brendan Eich developed JavaScript with syntax similar to C, but nobody believed that JavaScript would play a major role in development of commercial softwares. In 1997, JavaScript was made a standard through ECMA international. But what gave the required firepower to JavaScript from breaking out of just being a programming language to creating web pages are the
Now JavaScript is widely used in web pages, web servers, mobile apps, and IoT systems.
You ask me why JavaScript is used in building IoT systems? Here are my reasons.,
It is quite good at event-driven applications. In event driven applications, every device listens to various other events and responds to concerned events.
Event loops in JavaScript allow you run numerous tasks without waiting for other tasks to complete. This helps in responding to events in real time, handling multiple tasks parallelly, and allowing multiple devices to respond to the same event. This contributes to a great extent in saving precious battery power.
JavaScript has a garbage collector, which eliminates the need of explicitly freeing up the memory. This allows embedded developers to focus on other important aspects of development. The automatic freeing of the unused memory results in a stable product because the garbage collector eliminates memory leaks.
One drawback of garbage collector with constrained devices is trashing – the garbage collector running very often has an adverse impact on performance. This can be avoided with the JavaScript programming style which limits the creation of new objects to major state changes in the embedded device or application. This keeps the memory usage stable without running the garbage collector very often.
With the increased use of JavaScript in various applications, there are many JavaScript development resources available, such as
JavaScript developers in IoT have sophisticated frameworks and engines like CycloneJS, IoT.js, JerryScript, Duktape, etc. specifically designed for constrained devices.
A wide variety of hardware solutions in IoT, such as Raspberry Pi, Espruino, etc.. support Node.js. There are JavaScript-only microcontrollers such as Tessel 2 and Espruino which have proven to be very useful in IoT projects. Thousands of Node Package Manager (NPM) modules for Node.js such as PM2, Socket.io, Mocha etc. have been developed to enhance the power of Node.js in IoT.
End user scripting can be enabled by embedded devices using JavaScript because JavaScript is a managed execution environment where end-used scriptability is secure by safely sandboxing the scripts. End-used scripting brings new ideas and possibilities because the customization enabled by allows end-users, hobbyists, and professional programmers to script their devices and add new functionalities.
This is another crucial factor that makes JavaScript a suitable programming language for IoT. The open source nature of JavaScript makes it possible for programmers to make useful contributions to various JavaScript projects. This fosters creativity and brings in innovations to IoT enabled hardware, software, and network solutions.
Already JavaScript is a commonly used language across the Internet, so it makes absolute sense to include the same language in the devices which will be part of the Internet.
JavaScript is very easy to learn, so you can start coding in a short span of time. Consider a situation where a C programmer is asked to do parallel programming.
To do parallel programming in C, he has to be a “stud.” He has to know what he is doing. And here is this JavaScript thing; it is kind of a built-in feature. Now any 12-year-old can do parallel programming!
Currently, a majority of embedded programmers are using C. In the process of developing an IoT system, embedded programmers need not learn different syntax if they are using JavaScript. Syntax of JavaScript is very similar to C, hence an experienced embedded programmer just needs to invest a little time to understand and successfully modify JavaScript code.
Node.js has evolved as a robust technology which makes server-side implementation of JavaScript possible. The event-driven nature and asynchronous input-output (IO) model of Node.js makes it a perfect fit to build IoT systems.
A range of tech majors are leveraging the power of Node.js in building a network of devices, sensors, and smartphones; these can be controlled and manipulated remotely. Companies like Microsoft, IBM, and Samsung have already embraced Node.js as the preferred technology for their IoT development projects.
So now,

In our previous redis blog we gave a brief introduction on how to interface between python and redis. In this post, we will use Redis as a cache, to build the backend of our basic twitter app.
We first start the server, if it’s in a stopped state.
sudo service redis_6379 start
sudo service redis_6379 stopIn case you have not installed the redis server, you can install the server and configure it with python using the previous tutorial.
We will work on creating our own custom Twitter and post tweets to this. Users should be able to post tweets, and there should be a timeline forthe posts. The screenshot of the final product is shown below.

We will use flask and redis for this. Flask is a good python web microframework which lets you focus only on things you need. There is more focus on the modularity of your code base. Redis is a key-value datastore that can be used as a database. Redis is an excellent choice for caching and for constant real-time analysis of data coming in, hence redis is a great tool to build a twitter-like platform.
Let us start building the module. There are some build dependencies; therefore ensure the following dependencies are installed.
sudo apt-get install build-essential
sudo apt-get install python3-dev
sudo apt-get install libncurses5-devOnce done, fire-up a virtualenv and install the requirements.
virtualenv venv -p python3.5
source venv/bin/activate
wget https://raw.githubusercontent.com/infinite-Joy/retwis-py/master/requirements.txt
pip install -r requirements.txtCreate a folder structure of the following format.
mkdir retwis
cd retwisFlask lets us create the template files - layout.html, login.html and signup.html. These templates are designed using the Jinja2 templates which Flask uses. We can use template inheritance and login and signup pages will inherit from layout.html.
Check out the three template files shown below.
<!doctype html>
<title>Retwis</title>
<link rel="stylesheet" href="https://maxcdn.bootstrapcdn.com/bootstrap/3.3.6/css/bootstrap.min.css">
<link rel="stylesheet" type="text/css" href="{{ url_for('static', filename='style.css') }}">
<nav class="navbar navbar-default navbar-fixed-top">
<div class="container-fluid">
<div class="navbar-header">
<h1>Retwis</h1>
</div>
<div id="navbar" class="navbar-collapse collapse">
<ul class="nav navbar-nav navbar-right">
<li>
{% if not session.username %}
<a href="{{ url_for('login') }}">log in</a>
{% else %}
<a href="{{ url_for('logout') }}">log out</a>
{% endif %}
</li>
</ul>
</div>
</div>
</nav>
<div class="main-body">
<div class="container">
{% block body %}{% endblock %}
</div>
</div>
Note that we have abstracted out the common elements of all the pages. We have defined the header with the title and then in the body; if a session is present, there will be the login link, else there will be the logout link.
Check out the login and the signup html which are almost similar.
{% extends "layout.html" %}
{% block body %}
<h2>Login</h2>
{% if error %}<p class="error"><strong>Error:</strong> {{ error }}{% endif %}
<form action="{{ url_for('login') }}" method="post">
<div class="form-group">
<label for="username">Username</label>
<input class="form-control" type="text" name="username">
</div>
<div class="form-group">
<label for="password">Password</label>
<input class="form-control" type="password" name="password">
</div>
<button class="btn btn-default" type="submit">Login</button>
</form>
<a class="btn btn-default" href="{{ url_for('signup') }}">Sign up</a>
{% endblock %}
{% extends "layout.html" %}
{% block body %}
<h2>Signup</h2>
{% if error %}<p class="error"><strong>Error:</strong> {{ error }}{% endif %}
<form action="{{ url_for('signup') }}" method="post">
<div class="form-group">
<label for="username">Username</label>
<input class="form-control" type="text" name="username">
</div>
<div class="form-group">
<label for="password">Password</label>
<input class="form-control" type="password" name="password">
</div>
<button class="btn btn-default" type="submit">Sign up</button>
</form>
{% endblock %}
As you can see, if there is no error, then we define the username and the password fields that are bound with the “post” method.
We can now create the basic flask app and see if the two templates get rendered correctly. We create two endpoints for the templates and then render them. Check out the code below.
from flask import Flask
from flask import render_template
app = Flask(__name__)
DEBUG = True
@app.route('/signup')
def signup():
error = None
return render_template('signup.html', error=error)
@app.route('/')
def login():
error = None
return render_template('login.html', error=error)
if __name__ == "__main__":
app.run()
To run the server use the following command.
python views.pyOn your browser, open http://127.0.0.1:5000/signup

And hit http://127.0.0.1:5000/

You should be able to see the two pages above.
We will also need to create the home page which the user will fall back to once he is logged in. Create a home.html in the templates folder and then write the tweets block.
{% extends "layout.html" %}
{% block body %}
<form action="{{ url_for('home') }}" method="post">
<div class="form-group">
<input class="form-control" type="text" name="tweet" placeholder="What are you thinking?">
</div>
<button class="btn btn-default" type="submit">Post</button>
</form>
{% for post in timeline %}
<li class="tweet">
{{ post.username }} at {{ post.ts }}
{{ post.text }}
</li>
{% else %}
<h2>No posts!</h2>
{% endfor %}
{% endblock %}
As you see, if there are posts on the timeline, then list the username, time, and the text, else put “No posts” in header format. Let’s build the code for that in view.py and see how it looks.
@app.route('/home')
def home():
return render_template('home.html', timeline=[{"username": "dummy_username",
"ts": "today",
"text": "dummy text"}])
If you check out the url http://localhost:5000/home, you should get the page below.

Now that we have all the pages and have built the frontend, in the next post we will build the redis backend that will handle the user information, the session data, and the posts that the users submit.
We will be using redis to get user information. If you don't have redis-py already installed in your virtual environment, install it using pip.
pip install redisNext, we need to plugin redis to our flask app and see that it gets instantiated before each request.
import redis
from flask import Flask
from flask import render_template
app = Flask(__name__)
DEBUG = True
def init_db():
db = redis.StrictRedis(
host=DB_HOST,
port=DB_PORT,
db=DB_NO)
return db
@app.before_request
def before_request():
g.db = init_db()
# remaining code here.
We will interface the signup page with redis and on signing up, the user information should get populated in the redis datastore.
We change the signup function to the code below.
import redis
from flask import Flask
from flask import render_template
from flask import request
from flask import url_for
from flask import session
from flask import g
app = Flask(__name__)
# other code …
@app.route('/signup', methods=['GET', 'POST'])
def signup():
error = None
if request.method == 'GET':
return render_template('signup.html', error=error)
username = request.form['username']
password = request.form['password']
user_id = str(g.db.incrby('next_user_id', 1000))
g.db.hmset('user:' + user_id, dict(username=username, password=password))
g.db.hset('users', username, user_id)
session['username'] = username
return redirect(url_for('home'))
Here, we take the username and the password from the form and push them to the redis database. Note that we increment the keys by 1000. This is a standard for redis keys. For more information, consult the official docs.
We will also need to set a secret key to use session information which is used in the code above. You can read about sessions and how to set session keys from the official docs. We will also do a little bit of refactoring and keep the settings information together.
# import statements
app = Flask(__name__)
# settings
DEBUG = True
# I am using a SHA1 hash. Use a more secure algo in your PROD work
SECRET_KEY = '8cb049a2b6160e1838df7cfe896e3ec32da888d7'
app.secret_key = SECRET_KEY
# Redis setup
DB_HOST = 'localhost'
DB_PORT = 6379
DB_NO = 0
# def init_db(): ...
# def before_request(): ...
# def signup(): ...
# def login(): ...
# def home(): ...
if __name__ == "__main__":
app.run()
Check out the form now and try to submit some user information.

Check on the redis end and check out the values that have been populated.
? redis-cli
127.0.0.1:6379> HGETALL *
(empty list or set)
127.0.0.1:6379> KEYS *
1) "users"
2) "user:1000"
3) "next_user_id"
127.0.0.1:6379> HGETALL "users"
1) "hackerearth"
2) "1000"
127.0.0.1:6379> HGETALL "user:1000"
1) "username"
2) "hackerearth"
3) "password"
4) "hackerearth"
Once the session and signup functions work fine, we can then focus on the home page where people can login once they have signed up. These two pages should fall back safely to the home page.
@app.route('/', methods=['GET', 'POST'])
def login():
error = None
if request.method == 'GET':
return render_template('login.html', error=error)
username = request.form['username']
password = request.form['password']
user_id = str(g.db.hget('users', username), 'utf-8')
if not user_id:
error = 'No such user'
return render_template('login.html', error=error)
saved_password = str(g.db.hget('user:' + str(user_id), 'password'), 'utf-8')
if password != saved_password:
error = 'Incorrect password'
return render_template('login.html', error=error)
session['username'] = username
return redirect(url_for('home'))
The code tells us if the request method is “GET”, then we render the login page. This is the first page that comes up when we go to the page http://localhost:5000/.
After that, we will fill up the fields with the previous values. The entered username and password is pulled from the form. Using this username, we get the user ID from the redis database and this user ID is used to retrieve the password. This password is then matched with the entered password. If there is a match, then we will be redirected to the “home page.”
We now need to work on the home page. The home page is the biggest of the three modules as these do several things simultaneously. It should handle the session information. If the session information is not there, it should transfer to the login page. It should retrieve the posts of the user and push them to the redis database and get the data in turn. So we will replace the home function in views.py with the code below.
@app.route('/home', methods=['GET', 'POST'])
def home():
if not session:
return redirect(url_for('login'))
user_id = g.db.hget('users', session['username'])
if request.method == 'GET':
return render_template('home.html', timeline=_get_timeline(user_id))
text = request.form['tweet']
post_id = str(g.db.incr('next_post_id'))
g.db.hmset('post:' + post_id, dict(user_id=user_id,
ts=datetime.utcnow(), text=text))
g.db.lpush('posts:' + str(user_id), str(post_id))
g.db.lpush('timeline:' + str(user_id), str(post_id))
g.db.ltrim('timeline:' + str(user_id), 0, 100)
return render_template('home.html', timeline=_get_timeline(user_id))
def _get_timeline(user_id):
posts = g.db.lrange('timeline:' + str(user_id), 0, -1)
timeline = []
for post_id in posts:
post = g.db.hgetall('post:' + str(post_id, 'utf-8'))
timeline.append(dict(
username=g.db.hget('user:' + str(post[b'user_id'], 'utf-8'), 'username'),
ts=post[b'ts'],
text=post[b'text']))
return timeline
Note, the timeline part is handled in the _get_timeline function. We get the timeline from the redis database and then for all the posts we put the username, time and the post text to a timeline list. This list is returned to the home function, which takes the user tweet post and pushes it to redis, after which it renders the current posts in the timeline. We will also need to “import datetime.”
import redis
import datetime
from flask import Flask
from flask import render_template
from flask import request
from flask import url_for
from flask import session
from flask import g
from flask import redirect
# rest of the code
We need to build the url for logout for the template to work correctly.
@app.route('/logout')
def logout():
session.pop('username', None)
return redirect(url_for('login'))
Now, check it in the browser. Hit http://localhost:5000; login with your credentials. You should be able to post tweets now to the post.
Please refactor the code to make it more organized. Also, use Test Driven Development and good logging practises when building production-grade apps (although it isn’t in this post). Please find the whole code in this github repo.
A big shoutout to kushmansingh/retwis-py who inspired me to write the blog.
References

Artificial Intelligence (AI) has permeated virtually every industry, transforming operations and interactions. The tech recruitment sector is no exception, and AI’s influence shapes the hiring processes in revolutionary ways. From leveraging AI-powered chatbots for preliminary candidate screenings to deploying machine learning algorithms for efficient resume parsing, AI leaves an indelible mark on tech hiring practices.
Yet, amidst these promising advancements, we must acknowledge the other side of the coin: AI’s potential malpractices, including the likelihood of cheating on assessments, issues around data privacy, and the risk of bias against minority groups.
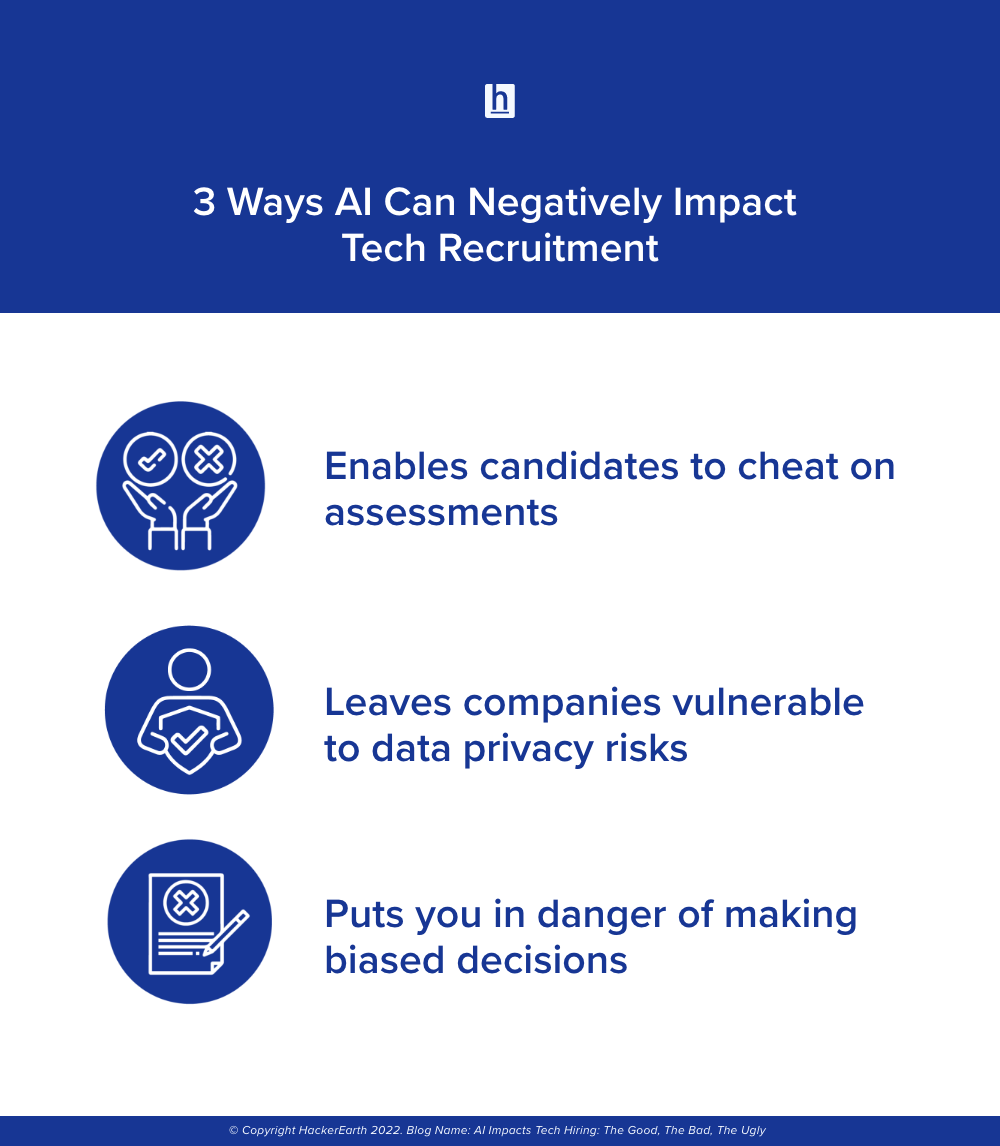
The introduction of AI in recruitment, while presenting significant opportunities, also brings with it certain drawbacks and vulnerabilities. Sophisticated technologies could enable candidates to cheat on assessments, misrepresent abilities and potential hiring mistakes. This could lead to hiring candidates with falsifying skills or qualifications, which can cause a series of negative effects like:
Your company could be left exposed to significant risks if your AI recruiting software is not robust enough to protect sensitive employee information. The implications for an organization with insufficient data security could be severe such as:
Perhaps the most critical issue of all is the potential for unconscious bias. The potential for bias in AI recruiting software stems from the fact that these systems learn from the data they are trained on. If the training data contains biases – for example, if it reflects a history of preferentially hiring individuals of a certain age, gender, or ethnicity – the AI system can learn and replicate these biases.
Even with unbiased data, if the AI’s algorithms are not designed to account for bias, they can inadvertently create it. For instance, a hiring algorithm that prioritizes candidates with more years of experience may inadvertently discriminate against younger candidates or those who have taken career breaks, such as for child-rearing or health reasons.
This replication and possible amplification of human prejudices can result in discriminatory hiring practices. If your organization’s AI-enabled hiring system is found to be biased, you could face legal action, fines, and penalties. Diversity is proven to enhance creativity, problem-solving, and decision-making. In contrast, bias in hiring can lead to a homogenous workforce, so its absence would likely result in a less innovative and less competitive organization.
Also read: What We Learnt From Target’s Diversity And Inclusion Strategy

How do you evaluate the appropriateness of using AI in hiring for your organization? Here are some strategies for navigating the AI revolution in HR. These steps include building support for AI adoption, identifying HR functions that can be integrated with AI, avoiding potential pitfalls of AI use in HR, collaborating with IT leaders, and so on.
Despite certain challenges, AI can significantly enhance tech recruitment processes when used effectively. AI-based recruitment tools can automate many manual recruiting tasks, such as resume screening and interview scheduling, freeing up time for recruiters to focus on more complex tasks. Furthermore, AI can improve the candidate’s experience by providing quick responses and personalized communications. The outcome is a more efficient, candidate-friendly process, which could lead to higher-quality hires.
Let’s look at several transformational possibilities chatbots can bring to human capital management for candidates and hiring teams. This includes automation and simplifying various tasks across domains such as recruiting, onboarding, core HR, absence management, benefits, performance management, and employee self-service resulting in the following:
Also read: 5 Steps To Create A Remote-First Candidate Experience In Recruitment

Additionally, candidates can leverage these AI-powered chatbots in a dialog flow manner to carry out various tasks. These tasks include the following:
These can also be utilized by your tech hiring teams for various purposes, such as:
Other AI recruiting technologies can also enhance the hiring process for candidates and hiring teams in the following ways:
These enhancements not only streamline the hiring process but also improve the quality of hires, reduce hiring biases, and improve the experience for everyone involved. The use of AI in hiring can indeed take it to the next level.
AI can dramatically reshape the recruitment landscape with the following key advancements:
Blockchain technology, renowned for its secure, transparent, and immutable nature, can revolutionize background checks. This process which can take anywhere from between a day to several weeks today for a single recruiter to do can be completed within a few clicks resulting in:
VR can provide immersive experiences that enhance various aspects of the tech recruitment process:
Also read: 6 Strategies To Enhance Candidate Engagement In Tech Hiring (+ 3 Unique Examples)
To summarize, AI in recruitment is a double-edged sword, carrying both promise and potential problems. The key lies in how recruiters use this technology, leveraging its benefits while vigilantly managing its risks. AI isn’t likely to replace recruiters or HR teams in the near future. Instead, you should leverage this tool to positively impact the entire hiring lifecycle.
With the right balance and careful management, AI can streamline hiring processes. It can create better candidate experiences, and ultimately lead to better recruitment decisions. Recruiters should continually experiment with and explore generative AI. To devise creative solutions, resulting in more successful hiring and the perfect fit for every open role.
“Every hire is an investment for a company. A good hire will give you a higher ROI; if it is a bad hire, it will cost you a lot of time and money.”
Especially in tech hiring!
An effective tech recruitment process helps you attract the best talents, reduce hiring costs, and enhance company culture and reputation.
Businesses increasingly depend on technical knowledge to compete in today’s fast-paced, technologically driven world. Online platforms that provide technical recruiting solutions have popped up to assist companies in finding and employing top talent in response to this demand.
The two most well-known platforms in this field are HackerEarth and Mettl. To help businesses make wise choices for their technical employment requirements, we will compare these two platforms’ features, benefits, and limitations in this article.
This comparison of Mettl alternative, HackerEarth and Mettl itself, will offer helpful information to help you make the best decision, whether you’re a small company trying to expand your tech staff or a massive organization needing a simplified recruiting process.
HackerEarth is based in San Francisco, USA, and offers enterprise software to aid companies with technical recruitment. Its services include remote video interviewing and technical skill assessments that are commonly used by organizations.
HackerEarth also provides a platform for developers to participate in coding challenges and hackathons. In addition, it provides tools for technical hiring such as coding tests, online interviews, and applicant management features. The hiring solutions provided by HackerEarth aid companies assess potential employees’ technical aptitude and select the best applicants for their specialized positions.
Mettl, on the other hand, offers a range of assessment solutions for various industries, including IT, banking, healthcare, and retail. It provides online tests for coding, linguistic ability, and cognitive skills. The tests offered by Mettl assist employers find the best applicants for open positions and make data-driven recruiting choices. Additionally, Mettl provides solutions for personnel management and staff training and development.

Because HackerEarth makes technical recruiting easy and fast, you must consider HackerEarth for technical competence evaluations and remote video interviews. It goes above and beyond to provide you with a full range of functions and guarantee the effectiveness of the questions in the database. Moreover, it is user-friendly and offers fantastic testing opportunities.
The coding assessments by HackerEarth guarantee the lowest time consumption and maximum efficiency. It provides a question bank of more than 17,000 coding-related questions and automated test development so that you can choose test questions as per the job role.
As a tech recruiter, you may need a clear understanding of a candidate’s skills. With HackerEarth’s code replay capability and insight-rich reporting on a developer’s performance, you can hire the right resource for your company.
Additionally, HackerEarth provides a more in-depth examination of your recruiting process so you can continuously enhance your coding exams and develop a hiring procedure that leads the industry.
HackerEarth and Mercer Mettl are the two well-known online tech assessment platforms that provide tools for managing and performing online examinations. We will examine the major areas where HackerEarth outperforms Mettl, thereby proving to be a great alternative to Mettl, in this comparison.
Also read: What Makes HackerEarth The Tech Behind Great Tech Teams
HackerEarth believes in upgrading itself and providing the most effortless navigation and solutions to recruiters and candidates.
HackerEarth provides various tools and capabilities to create and administer online tests, such as programming tests, multiple-choice questions, coding challenges, and more. The software also has remote proctoring, automatic evaluation, and plagiarism detection tools (like detecting the use of ChatGPT in coding assessments). On the other side, Mettl offers comparable functionality but has restricted capabilities for coding challenges and evaluations.
HackerEarth: It has a user-friendly interface that is simple to use and navigate. It makes it easy for recruiters to handle evaluations without zero technical know-how. The HackerEarth coding platform is also quite flexible and offers a variety of pre-built exams, including coding tests, aptitude tests, and domain-specific examinations. It has a rich library of 17,000+ questions across 900+ skills, which is fully accessible by the hiring team. Additionally, it allows you to create custom questions yourself or use the available question libraries.
Also read: How To Create An Automated Assessment With HackerEarth
Mettl: It can be challenging for a hiring manager to use Mettl efficiently since Mettl provides limited assessment and question libraries. Also, their team creates the test for them rather than giving access to hiring managers. This results in a higher turnaround time and reduces test customization possibilities since the request has to go back to the team, they have to make the changes, and so forth.
HackerEarth: You may assess applicant performance and pinpoint areas for improvement with the help of HackerEarth’s full reporting and analytics tools. Its personalized dashboards, visualizations, and data exports simplify evaluating assessment results and real-time insights.
Most importantly, HackerEarth includes code quality scores in candidate performance reports, which lets you get a deeper insight into a candidate’s capabilities and make the correct hiring decision. Additionally, HackerEarth provides a health score index for each question in the library to help you add more accuracy to your assessments. The health score is based on parameters like degree of difficulty, choice of the programming language used, number of attempts over the past year, and so on.
Mettl: Mettl online assessment tool provides reporting and analytics. However, there may be only a few customization choices available. Also, Mettle does not provide code quality assurance which means hiring managers have to check the whole code manually. There is no option to leverage question-based analytics and Mettl does not include a health score index for its question library.
Adopting this platform may be challenging if you want highly customized reporting and analytics solutions.
Also read: HackerEarth Assessments + The Smart Browser: Formula For Bulletproof Tech Hiring
HackerEarth: The security and privacy of user data are top priorities at HackerEarth. The platform protects data in transit and at rest using industry-standard encryption. Additionally, all user data is kept in secure, constantly monitored data centers with stringent access controls.
Along with these security measures, HackerEarth also provides IP limitations, role-based access controls, and multi-factor authentication. These features ensure that all activity is recorded and audited and that only authorized users can access sensitive data.
HackerEarth complies with several data privacy laws, such as GDPR and CCPA. The protection of candidate data is ensured by this compliance, which also enables businesses to fulfill their legal and regulatory responsibilities.
Mettl: The security and data privacy features of Mettl might not be as strong as those of HackerEarth. The platform does not provide the same selection of security measures, such as IP limitations or multi-factor authentication. Although the business asserts that it complies with GDPR and other laws, it cannot offer the same amount of accountability and transparency as other platforms.
Even though both HackerEarth and Mettl include security and data privacy measures, the Mettle alternative, HackerEarth’s platform is made to be more thorough, open, and legal. By doing this, businesses can better guarantee candidate data’s security and ability to fulfill legal and regulatory requirements.
HackerEarth: To meet the demands of businesses of all sizes, HackerEarth offers a variety of customizable pricing options. The platform provides yearly and multi-year contracts in addition to a pay-as-you-go basis. You can select the price plan that best suits their demands regarding employment and budget.
HackerEarth offers chat customer support around the clock. The platform also provides a thorough knowledge base and documentation to assist users in getting started and troubleshooting problems.
Mettl: The lack of price information on Mettl’s website might make it challenging for businesses to decide whether the platform fits their budget. The organization also does not have a pay-as-you-go option, which might be problematic.
Mettl offers phone and emails customer assistance. However, the business website lacks information on support availability or response times. This lack of transparency may be an issue if you need prompt and efficient help.
HackerEarth: The interface on HackerEarth is designed to be simple for both recruiters and job seekers. As a result of the platform’s numerous adjustable choices for test creation and administration, you may design exams specifically suited to a job role. Additionally, the platform provides a selection of question types and test templates, making it simple to build and take exams effectively.
In terms of the candidate experience, HackerEarth provides a user-friendly interface that makes navigating the testing procedure straightforward and intuitive for applicants. As a result of the platform’s real-time feedback and scoring, applicants may feel more motivated and engaged during the testing process. The platform also provides several customization choices, like branding and message, which may assist recruiters in giving prospects a more exciting and tailored experience.
Mettl: The platform is intended to have a steeper learning curve than others and be more technical. It makes it challenging to rapidly and effectively construct exams and can be difficult for applicants unfamiliar with the platform due to its complex interface.
Additionally, Mettl does not provide real-time feedback or scoring, which might deter applicants from participating and being motivated by the testing process.
Also read: 6 Strategies To Enhance Candidate Engagement In Tech Hiring (+ 3 Unique Examples)
According to G2, HackerEarth and Mettl have 4.4 reviews out of 5. Users have also applauded HackerEarth’s customer service. Many agree that the staff members are friendly and quick to respond to any problems or queries. Overall, customer evaluations and feedback for HackerEarth point to the platform as simple to use. Both recruiters and applicants find it efficient.
Mettl has received mixed reviews from users, with some praising the platform for its features and functionality and others expressing frustration with its complex and technical interface.

Recruiting and selecting the ideal candidate demands a significant investment of time, attention, and effort.
This is where tech recruiting platforms like HackerEarth and Mettl have got you covered. They help streamline the whole process.Both HackerEarth and Mettl provide a wide variety of advanced features and capabilities for tech hiring.
We think HackerEarth is the superior choice. Especially, when contrasting the two platforms in terms of their salient characteristics and functioning. But, we may be biased!
So don’t take our word for it. Sign up for a free trial and check out HackerEarth’s offerings for yourself!

 Our AI-enabled Smart Browser takes frequent snapshots via the webcam, throughout the assessment.
Consequently, it is impossible to copy-paste code or impersonate a candidate.The browser prevents the following
candidate actions and facilitates thorough monitoring of the assessment:
Our AI-enabled Smart Browser takes frequent snapshots via the webcam, throughout the assessment.
Consequently, it is impossible to copy-paste code or impersonate a candidate.The browser prevents the following
candidate actions and facilitates thorough monitoring of the assessment:In today’s fast-paced world, recruiting talent has become increasingly complicated. Technological advancements, high workforce expectations and a highly competitive market have pushed recruitment agencies to adopt innovative strategies for recruiting various types of talent. This article aims to explore one such recruitment strategy – headhunting.
In headhunting, companies or recruitment agencies identify, engage and hire highly skilled professionals to fill top positions in the respective companies. It is different from the traditional process in which candidates looking for job opportunities approach companies or recruitment agencies. In headhunting, executive headhunters, as recruiters are referred to, approach prospective candidates with the hiring company’s requirements and wait for them to respond. Executive headhunters generally look for passive candidates, those who work at crucial positions and are not on the lookout for new work opportunities. Besides, executive headhunters focus on filling critical, senior-level positions indispensable to companies. Depending on the nature of the operation, headhunting has three types. They are described later in this article. Before we move on to understand the types of headhunting, here is how the traditional recruitment process and headhunting are different.
Headhunting is a type of recruitment process in which top-level managers and executives in similar positions are hired. Since these professionals are not on the lookout for jobs, headhunters have to thoroughly understand the hiring companies’ requirements and study the work profiles of potential candidates before creating a list.
In the traditional approach, there is a long list of candidates applying for jobs online and offline. Candidates approach recruiters for jobs. Apart from this primary difference, there are other factors that define the difference between these two schools of recruitment.
AspectHeadhuntingTraditional RecruitmentCandidate TypePrimarily passive candidateActive job seekersApproachFocused on specific high-level rolesBroader; includes various levelsScopeproactive outreachReactive: candidates applyCostGenerally more expensive due to expertise requiredTypically lower costsControlManaged by headhuntersManaged internally by HR teams
All the above parameters will help you to understand how headhunting differs from traditional recruitment methods, better.
Direct headhunting: In direct recruitment, hiring teams reach out to potential candidates through personal communication. Companies conduct direct headhunting in-house, without outsourcing the process to hiring recruitment agencies. Very few businesses conduct this type of recruitment for top jobs as it involves extensive screening across networks outside the company’s expanse.
Indirect headhunting: This method involves recruiters getting in touch with their prospective candidates through indirect modes of communication such as email and phone calls. Indirect headhunting is less intrusive and allows candidates to respond at their convenience.Third-party recruitment: Companies approach external recruitment agencies or executive headhunters to recruit highly skilled professionals for top positions. This method often leverages the company’s extensive contact network and expertise in niche industries.
Finding highly skilled professionals to fill critical positions can be tricky if there is no system for it. Expert executive headhunters employ recruitment software to conduct headhunting efficiently as it facilitates a seamless recruitment process for executive headhunters. Most software is AI-powered and expedites processes like candidate sourcing, interactions with prospective professionals and upkeep of communication history. This makes the process of executive search in recruitment a little bit easier. Apart from using software to recruit executives, here are the various stages of finding high-calibre executives through headhunting.
Once there is a vacancy for a top job, one of the top executives like a CEO, director or the head of the company, reach out to the concerned personnel with their requirements. Depending on how large a company is, they may choose to headhunt with the help of an external recruiting agency or conduct it in-house. Generally, the task is assigned to external recruitment agencies specializing in headhunting. Executive headhunters possess a database of highly qualified professionals who work in crucial positions in some of the best companies. This makes them the top choice of conglomerates looking to hire some of the best talents in the industry.
Once an executive headhunter or a recruiting agency is finalized, companies conduct meetings to discuss the nature of the role, how the company works, the management hierarchy among other important aspects of the job. Headhunters are expected to understand these points thoroughly and establish a clear understanding of their expectations and goals.
Headhunters analyse and understand the requirements of their clients and begin creating a pool of suitable candidates from their database. The professionals are shortlisted after conducting extensive research of job profiles, number of years of industry experience, professional networks and online platforms.
Once the potential candidates have been identified and shortlisted, headhunters move on to get in touch with them discreetly through various communication channels. As such candidates are already working at top level positions at other companies, executive headhunters have to be low-key while doing so.
In this next step, extensive screening and evaluation of candidates is conducted to determine their suitability for the advertised position.
Compensation is a major topic of discussion among recruiters and prospective candidates. A lot of deliberation and negotiation goes on between the hiring organization and the selected executives which is facilitated by the headhunters.
Things come to a close once the suitable candidates accept the job offer. On accepting the offer letter, headhunters help finalize the hiring process to ensure a smooth transition.
The steps listed above form the blueprint for a typical headhunting process. Headhunting has been crucial in helping companies hire the right people for crucial positions that come with great responsibility. However, all systems have a set of challenges no matter how perfect their working algorithm is. Here are a few challenges that talent acquisition agencies face while headhunting.
Despite its advantages, headhunting also presents certain challenges:
Cost Implications: Engaging headhunters can be more expensive than traditional recruitment methods due to their specialized skills and services.
Time-Consuming Process: While headhunting can be efficient, finding the right candidate for senior positions may still take time due to thorough evaluation processes.
Market Competition: The competition for top talent is fierce; organizations must present compelling offers to attract passive candidates away from their current roles.
Although the above mentioned factors can pose challenges in the headhunting process, there are more upsides than there are downsides to it. Here is how headhunting has helped revolutionize the recruitment of high-profile candidates.
Headhunting offers several advantages over traditional recruitment methods:
Access to Passive Candidates: By targeting individuals who are not actively seeking new employment, organisations can access a broader pool of highly skilled professionals.
Confidentiality: The discreet nature of headhunting protects both candidates’ current employment situations and the hiring organisation’s strategic interests.
Customized Search: Headhunters tailor their search based on the specific needs of the organization, ensuring a better fit between candidates and company culture.
Industry Expertise: Many headhunters specialise in particular sectors, providing valuable insights into market dynamics and candidate qualifications.
Although headhunting can be costly and time-consuming, it is one of the most effective ways of finding good candidates for top jobs. Executive headhunters face several challenges maintaining the g discreetness while getting in touch with prospective clients. As organizations navigate increasingly competitive markets, understanding the nuances of headhunting becomes vital for effective recruitment strategies. To keep up with the technological advancements, it is better to optimise your hiring process by employing online recruitment software like HackerEarth, which enables companies to conduct multiple interviews and evaluation tests online, thus improving candidate experience. By collaborating with skilled headhunters who possess industry expertise and insights into market trends, companies can enhance their chances of securing high-caliber professionals who drive success in their respective fields.
The job industry is not the same as it was 30 years ago. Progresses in AI and automation have created a new work culture that demands highly skilled professionals who drive innovation and work efficiently. This has led to an increase in the number of companies reaching out to external sources of recruitment for hiring talent. Over the years, we have seen several job aggregators optimise their algorithms to suit the rising demand for talent in the market and new players entering the talent acquisition industry. This article will tell you all about how external sources of recruitment help companies scout some of the best candidates in the industry, the importance of external recruitment in organizations across the globe and how it can be leveraged to find talent effectively.
External sources refer to recruitment agencies, online job portals, job fairs, professional associations and any other organizations that facilitate seamless recruitment. When companies employ external recruitment sources, they access a wider pool of talent which helps them find the right candidates much faster than hiring people in-house. They save both time and effort in the recruitment process.
Online resume aggregators like LinkedIn, Naukri, Indeed, Shine, etc. contain a large database of prospective candidates. With the advent of AI, online external sources of recruitment have optimised their algorithms to show the right jobs to the right candidates. Once companies figure out how to utilise job portals for recruitment, they can expedite their hiring process efficiently.
Ours is a generation that thrives on social media. To boost my IG presence, I have explored various strategies, from getting paid Instagram users to optimizing post timing and engaging with my audience consistently. Platforms like FB an IG have been optimized to serve job seekers and recruiters alike. The algorithms of social media platforms like Facebook and Instagram have been optimised to serve job seekers and recruiters alike. Leveraging them to post well-placed ads for job listings is another way to implement external sources of recruitment strategies.
Referrals are another great external source of recruitment for hiring teams. Encouraging employees to refer their friends and acquaintances for vacancies enables companies to access highly skilled candidates faster.
Hiring freshers from campus allows companies to train and harness new talent. Campus recruitment drives are a great external recruitment resource where hiring managers can expedite the hiring process by conducting screening processes in short periods.
Companies who are looking to fill specific positions with highly skilled and experienced candidates approach external recruitment agencies or executive headhunters to do so. These agencies are well-equipped to look for suitable candidates and they also undertake the task of identifying, screening and recruiting such people.
This is a win-win situation for job seekers and hiring teams. Job fairs allow potential candidates to understand how specific companies work while allowing hiring managers to scout for potential candidates and proceed with the hiring process if possible.
The role of recruitment agencies in talent acquisition is of paramount importance. They possess the necessary resources to help companies find the right candidates and facilitate a seamless hiring process through their internal system. Here is how external sources of recruitment benefit companies.
External recruitment resources are a great way for companies to hire candidates with diverse professional backgrounds. They possess industry-relevant skills which can be put to good use in this highly competitive market.
Candidates hired through external recruitment resources come from varied backgrounds. This helps them drive innovation and run things a little differently, thus bringing in a fresh approach to any project they undertake.
Companies cannot hire anyone to fill critical roles that require highly qualified executives. This task is assigned to executive headhunters who specialize in identifying and screening high-calibre candidates with the right amount of industry experience. Huge conglomerates and companies seek special talent through external recruiters who have carved a niche for themselves.
Now that you have learnt the different ways in which leveraging external sources of recruitment benefits companies, let’s take a look at some of the best practices of external recruitment to understand how to effectively use their resources.
Identifying, reaching out to and screening the right candidates requires a robust working system. Every system works efficiently if a few best practices are implemented. For example, hiring through social media platforms requires companies to provide details about their working environment, how the job is relevant to their audience and well-positioned advertisements. The same applies to the other external sources of recruitment. Here is how you can optimise the system to ensure an effective recruitment process.
Detail Responsibilities: Clearly outline the key responsibilities and expectations for the role.
Highlight Company Culture: Include information about the company’s mission, values, and growth opportunities to attract candidates who align with your organizational culture.
Diversify Sources: Use a mix of job boards, social media platforms, recruitment agencies, and networking events to maximize reach. Relying on a single source can limit your candidate pool.
Utilize Industry-Specific Platforms: In addition to general job boards, consider niche job sites that cater to specific industries or skill sets
Simplify Applications: Ensure that the application process is user-friendly. Lengthy or complicated forms can deter potential candidates from applying.
Mobile Optimization: Many candidates use mobile devices to apply for jobs, so ensure your application process is mobile-friendly.
Reach Out to Passive Candidates: Actively seek out candidates who may not be actively looking for a job but could be a great fit for your organization. Use LinkedIn and other professional networks for this purpose.
Maintain a Talent Pool: Keep a database of previous applicants and strong candidates for future openings, allowing you to reach out when new roles become available.
Promote Job Openings: Use social media platforms like LinkedIn, Facebook, and Twitter to share job postings and engage with potential candidates. This approach can also enhance your employer brand
Conduct Background Checks: There are several ways of learning about potential candidates. Checking out candidate profiles on job boards like LinkedIn or social media platforms can give companies a better understanding of their potential candidates, thus confirming whether they are the right fit for the organization.
Analyze Recruitment Metrics: Track key metrics such as time-to-hire, cost-per-hire, and source effectiveness. This data can help refine your recruitment strategies over time. Using external hiring software like HackeEarth can streamline the recruitment process, thus ensuring quality hires without having to indulge internal resources for the same.
Use Predictive Analytics: In this age of fast paced internet, everybody makes data-driven decisions. Using predictive analytics to study employee data will help companies predict future trends, thus facilitating a productive hiring process.
External sources of recruitment play a very important role in an organization’s talent acquisition strategy. By employing various channels of recruitment such as social media, employee referrals and campus recruitment drives, companies can effectively carry out their hiring processes. AI-based recruitment management systems also help in the process. Implementing best practices in external recruitment will enable organizations to enhance their hiring processes effectively while meeting their strategic goals.













